
"האפליקציה לא זזה לי?" חווית משתמש – האתגר המרכזי בעידן המודרני
באופן מסורתי פתרונות ניטור חווית משתמש פותחו עבור אפליקציות אשר הוטמעו בדאטה סנטר של הארגון, האימוץ המסיבי של תוכנה כשירות (SaaS) ושירותי ענן הביא עמו אתגרים חדשים למערכות אילו הדוחפות את גבולות הארגון ושוברות את הגישות המסורתיות. במאמר זה נדון מדוע הפתרונות הקיימים בשוק אינם מתאימים לארגון המודרני ונסקור את גישה חדשה שתענה על האתגרים החדשים.

מעבר מדאטה סנטר מקומי לאפליקציות ענן
ארגונים חווים היום שינוי מהותי, אימוץ של אפליקציות ענן (SaaS) כגון:
Salesforce, ServiceNow, Box אשר מחליפות את האפליקציות המסורתיות שהיו מותקנות בדאטה סנטר
מצמצם את העלויות ה-CAPEX של האפליקציות והתשתיות בדאטה סנטר ועלויות אלו עוברות למודל של Pay as you grow.
יחד עם זאת, שינוי זה מסתמך על קישוריות מהרשת הארגונית ל-Internet.
יישומים שבעבר פעלו בתוך רשת ארגונית מבוקרת פועלים כעת בכל מקום בענן, תוך הסתמכות על ביצועי Best effort של רשת האינטרנט.
האתגר עם ארכיטקטורות ארגוניות מסורתיות
על פי גרטנר, "שיטות התכנון של WAN ב-10 עד 15 השנים האחרונות התמקדו באיחוד וריכוז של יישומים ובקרות אבטחה במרכז הנתונים הארגוני".
מסיבות שונות, הרשת תוכננה כך שהכניסה והיציאה צומצמו וה דאטה סנטר או האתר המרכזי יהוו שער כניסה ויציאה מהרשת.
כאשר תעבורת האינטרנט של המשתמשים מנותבת דרך האתרים המרכזים של הארגון, לרוב תפגע חווית המשתמש בעיקר בעת שימוש באפליקציות SaaS וגם שמתעוררת תקלה מאוד קשה למצוא את מקור הבעיה.
אתגר זה מורגש אפילו יותר כאשר אנו משתמשים באפליקציה שהיא Chatty כלומר על כל פעולה שאנו מבצעים באפליקציה,יש הרבה פעילות בין "המשתמש" לשרת.
מצב זה יוצר איטיות וחוסר אפקטיביות של האפליקציה.
אתגר נוסף שקיים בארכיטקטורה המסורתית זה רוחב הפס ועלותו כאשר כל המשתמשים והאתרים נכנסים ויוצאים מהארגון מהאתר המרכזי.
ביצועי רשת של יישומי SaaS
חווית המשתמש של לקוח SaaS מורכבת משלושה אבני בניין:
רשת הארגון, האינטרנט והאפליקציה, כאשר מדדי הרשת העיקריים הם:
- שיהוי (latency) – השהיית רשת מוגדרת כזמן הלוך ושוב (RTT) בין הלקוח לשרת, השהיית הרשת תלויה בעיקר במרחק הפיזי בין נקודות הקצה לדוגמא שרת לקוח ובנוסף מעומס הרשת.
- אובדן מנות (packet loss) – אובדן מנות עלול לגרום לשידורים חוזרים (retransmit) של TCP ולהנמיך את תפוקת החיבור.
- קיבולת ורוחב פס זמין – קיבולת בין שתי נקודות קצה הוא קצב הנתונים המרבי שניתן להשיג בהיעדר תנועה חוצה.
רוחב הפס זמין הקובע את מהירות חיבורי TCP.
באופן כללי רוחב הפס מושפע מעלות וזמינות טכנולוגית. - יציבות פרוטוקולי ניתוב – השיקול בבחירת הניתוב בצורה האופטימלית ביותר ברשת האינטרנט שונה מאוד ולעיתים הניתובים נבחרים משיקולים כלכליים ולאו דווקא הנתיב היעיל או הטוב ביותר,
דבר אשר יכול לגרום לפגיעה בביצועים או לאי זמינות השירות. - רשת אלחוט (802.11) – תכנון רשת האלחוט או שימוש בציוד לא מתאים, הינה תופעה נפוצה לפגיעה בחווית המשתמש ולרוב קשה מאוד לאבחון בשל המגבלה בגישה לציוד המשתמש.
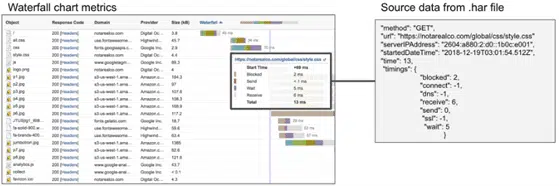
ביצועי יישומי WEB
ביצועי יישום WEB מאופיינים ע"י טעינת הדף בדפדפן עבור כל מרכיביו: תמונה, וידאו, פונט וכד',
כאשר חלקם יכולים להגיע אף מאתר צד שלישי או חיצוני לנותן שירותי ה-SaaS.
ישנם כמה מדדים מרכזיים שמשפיעים על חווית המשתמש או איך שהמשתמש תופס את המהירות שבה הדף נטען.
- Time-to-first-byte: זמן בדיקת DNS + זמן חיבור TCP + זמן קבלה;
מדד זה נקרא גם זמן תגובה
והוא קירוב טוב של הזמן שלוקח לשרת להתחיל לשלוח נתונים למשתמש. - זמן טעינת העמוד: הזמן שלוקח לדפדפן להפעיל את תהליך הטעינה של הדף.
זה כולל את הזמן שלוקח להוריד את ה- HTML, לנתח את Markup,
לעבד CSS, לעבד את הדף ולהוריד את כל התמונות בדף. - זמן הטרנזקציה: הזמן שבין שלב ההתחלה לשלב הסיום בסקריפט אשר מדמה פעולות משתמש בקבוצת דפים (לדוגמה, כניסה לאתר).
שיטות מומלצות בניטור אפליקציות SaaS
אחד היתרונות הגדולים של יישומי SaaS הוא היכולת להיכנס ולהתחיל לעבוד ללא מחזורי היישום הארכאיים של תוכנה ארגונית מסורתיות.
ניהול ביצועים של יישומי SaaS לא צריך להיות מחשבה שלאחר מכן.
ארגונים צריכים להעריך את ביצועי היישומים כחלק מתהליך ההערכה והבחירה של הספקים.
זה קריטי במיוחד כאשר משתמשים הם פזורים על פני סניפים רבים.
ולכן הגדרת בדיקות תקופתיות שחוזרות על התנהגות משתמש מסוימת ממספר סניפים
היא דרך טובה לעקוב אחר התנהגות היישום על פני זמן ומרחב.
הבטחת ביצועים טובים של שירותי SaaS תלויה במידה רבה בשיתוף פעולה הדוק בין צוותי תפעול הרשת, בעלי היישומים וספק ה- SaaS.
ישנם, שני היבטים שיש לשים לב אליהם הם Provisioning וניטור.
Provisioning
ניתוב: ארגונים צריכים לוודא כאשר הם מבצעים Backhauling של התעבורה הם לא יוצרים צוואר בקבוק עבור שירותי ה-SaaS ויש לוודא שהשיהוי מהמשתמש ליציאה מהארגון הוא נמוך, או לחילופין להשתמש בטכנולוגיות שמאפשרות יציאה לאינטרנט מהאתר המרוחק כגון split tunneling/
DNS: לרוב ארגונים ישתמשו בשרת DNS פנימי ויחסמו גישה ל-DNS צד שלישי.
במידה והלקוח ממוקם רחוק מהשירות או לחילופין היציאה מהארגון מאזור גיאוגרפי אחר, הלקוח יקבל שירות שאינו אופטימלי.
קיבולת: בהתאם לאופי השירות לקיבולת הרשת יש השפעה רבה על ביצועי השירות, על צוות ה-IT להבין את התנהגות השירות ולבחון האם נדרש ליישם מנגנונים כגון QoS ברשת.
מיקום השירות: חלק מיישומי SaaS מתארחים במרכז נתונים ספציפי שהלקוח יכול לבחור.
תהליך הבחירה צריך לכלול את החוויה של משתמשים ברחבי העולם, תוך מתן תשומת לב מיוחדת למשתמשים בשווקים מרוחקים שעשויים להיות בעלי עיכובים גבוהים למרכז הנתונים המארח את מופע ה- SaaS של הלקוח.
ניטור
בחירת כלי הניטור: בעת אימוץ שירות SaaS, על צוות ה-IT לנטר את הרשת והתשתיות בתוך הארגון,
באמצעות כלי שייסע זיהוי מקור הבעיה והאם הוא נמצא בארגון, באינטרנט או בספק ה-SaaS.
בתום התהליך ייתן המלצה לפתרון.
מתודולוגית בדיקות: במטרה לבודד את התקלה, ההמלצה היא לנטר בשכבות לדוגמא DNS, HTTP והרשת,
ולבצע קורולוציה בין כל אחת משכבות.
בנוסף אנו ממליצים לבחון את סביבת ה-backend במטרה לוודא זמני תגובה רצויים וצפויים.
בדיקה נוספת מומלצת, היא חיקוי של משתמש באתר וביצוע הבדיקות כפי שהמשתמש חווה.
פתרון תקלות: ברגע שצוות ה-IT, מזהה את התקלה ומצליח לבודד אותה, פתרון מהיר הוא המענה לחזרה לשגרה וכאשר מדובר על ענן ציבורי זה לא תמיד קל משום שמדובר על שיתוף בין מגוון רחב של צוותים בתוך ה-IT, ספק האינטרנט וספק שירות ה-SaaS.
אופטימלי שנרצה לבחור פתרון אשר יאפשר שיתוף מידע בין צוותים ויאחד את הבדיקות לפתרון מרכזי לככל הצוותים.
הצורך בבחירת מערכת ניטור מתאימה
באופן מסורתי, ארגונים פרסו יישומים בסביבות ה-IT שלהם כחלק מחבילת תוכנה, למשל CRM, דואר אלקטרוני.
כאשר עובדים התלוננו על בעיות ביצועים, התגובה המיידית היתה לפרוס מוצרים שמדדו התנהגות בצד היישום,
או על ידי מכשור היישום לניתוח שורות קוד או על ידי ניתוח תעבורת רשת.
רוב מוצרי ניהול הביצועים הארגוניים נבנו עבור יישומים שנשלטו ישירות על ידי הארגון.
המציאות היא שהאינטרנט הפך לעמוד השדרה של הארגון המודרני.
ייתכן שרוב צוותי ה- IT אפילו לא מודעים למקום שממנו מועברים היישומים שעליהם הם מסתמכים.
המספר הממוצע של קפיצות רשת שהמשתמשים צריכים לעבור גדל באופן דרסטי, ואספקת היישומים הפכה למפתח להבטחת ביצועים טובים.
המשמעות היא שלמשתמשים באתרי הקצה עלולים לחוות בעיות בחווית המשתמש בשירותי הענן גם אם אין בעיה בשירות, נוסיף לזה את המגבלה של הניטור שירותי ענן או את האינטרנט וצוותי ה-IT חווים הרבה אתגרים במציאת מקור הבעיה.
על מנת להתמודד ארגונים נדרשים לבחון את פתרונות הניטור שלהם ומה נדרש על מנת לנטר שירותי ענן.
הגישה של ThousenEyes
ThousendEyes מספק נראות לביצועי הרשת והיישומים בתוך סביבות ארגוניות ומסייע לצוותי ה-תפעול והרשת באיתור מקור הבעיה ומצמצם את הטיפול בתקלה לדקות ספורות.
ThousendEyes מתחבר לכל שכבה ביישום ומאפשר לצוות התפעול לקפוץ משכבה לשכבה בכדי לזהות בעיות בסיסיות.
כל שכבה ממפה תת-מערכת אחרת של היישום ביחד עם המדדים היחודיים לה.
Thousendeyes נפרס באמצעות סוכני Enterprise או ענן כדי לספק כיסוי רחב הן בתוך הארגון והן מנקודת מבט חיצונית.







 Enterprise Networking
למה Platform Engineering פופולרית פתאום, ואיך בונים IDP שמבוססת עליה?
Enterprise Networking
למה Platform Engineering פופולרית פתאום, ואיך בונים IDP שמבוססת עליה?
 Enterprise Networking
חשיבה מחדש על אסטרטגיות אחסון עבור יישומי בינה מלאכותית – AI
Enterprise Networking
חשיבה מחדש על אסטרטגיות אחסון עבור יישומי בינה מלאכותית – AI
 Enterprise Networking
סייבר, ענן וחווית משתמש: ההכרזות המשמעותיות מכנס Cisco Live 2024
Enterprise Networking
סייבר, ענן וחווית משתמש: ההכרזות המשמעותיות מכנס Cisco Live 2024
 Enterprise Networking
הקו הסגול של הרכבת הקלה מתקרב: בינת פרויקטים משולבים נבחרה להקים את מערך התקשוב של הקו
Enterprise Networking
הקו הסגול של הרכבת הקלה מתקרב: בינת פרויקטים משולבים נבחרה להקים את מערך התקשוב של הקו
 Enterprise Networking
AI – אתגר קשה להתמודדות בצורה מסורתית, לצד הזדמנות
Enterprise Networking
AI – אתגר קשה להתמודדות בצורה מסורתית, לצד הזדמנות
 Enterprise Networking
ניטור מבצעי: בואו להכיר את יכולות SolarWinds ב-Bynet EXPO 2024
Enterprise Networking
ניטור מבצעי: בואו להכיר את יכולות SolarWinds ב-Bynet EXPO 2024